




- Регистрация
- 7 Фев 2020
- Сообщения
- 525
- Реакции
- 98
- Репутация
- 147
SHA-1 (Secure Hash Algorithm 1) был разработан в 1993 году государственным агентством США по стандартизации (NIST) и опубликован в 1995 соответственно. Он широко использовался в приложениях и протоколах безопасности, включая TLS , SSL , PGP , SSH , IPsec и S / MIME . SHA как и MDA относится к семейству хеш-функций и был в свое время популярным стандартом сжатия сообщений.
С 2010 года многие организации рекомендовали заменить его на SHA-2 или SHA-3. Такие компании, как Microsoft, Google или Mozilla, объявили по несколко раз, что их браузеры прекратят поддерживать SHA-1 сначала к 2016, потом 17, ну, вот буквально с 1 января google перестал поддержку...
Работа алгоритма
SHA-1 работает путем подачи сообщения в виде битовой строки и создания 160-битного значения хеш-функции, известного как дайджест сообщения .
Дайджест сообщения SHA-1 оценивается с использованием дополненного сообщения. При оценке используются два буфера, каждый из которых состоит из пяти 32-битных слов и последовательности из восьмидесяти 32-битных слов. Слова первого буфера из пяти слов помечены как A, B, C, D и E. Слова второго буфера из пяти слов помечены как H0, H1, H2, H3 и H4 . Слова последовательности из восьмидесяти слов обозначены как W0, W1, W2, W 79. SHA1 обрабатывает блоки по 512 бит при оценке дайджеста сообщения. Весь экстент по длине дайджеста сообщения должен быть кратным 512. В архитектуре SHA-1 для повышения пропускной способности одновременно применяются разнообразные методы ускорения, такие как предварительное вычисление, развертывание цикла и конвейерная обработка.
Алгоритм
(псевдокод)
Функции используемые в алгоритме в i-х итерациях:
Предположим, что сообщение 'abc' должно быть закодировано с использованием SHA-1, и в двоичном виде оно выглядит, как:
3) Дополненный ввод, полученный выше, после этого делится на 512-битные порции, и каждый фрагмент дополнительно делится на шестнадцать 32-битных слов. В случае 'abc' есть только один фрагмент, так как общее сообщение составляет менее чем 512 бит.
4) Для каждого блока используется 80 итераций, необходимых для хеширования, и выполняются следующие шаги для каждого блока:
1.Для итераций с 16 по 79 выполняется следующеее:
5) Теперь сохраняем значения хеш-функции, определенные на шаге 1:
С 2010 года многие организации рекомендовали заменить его на SHA-2 или SHA-3. Такие компании, как Microsoft, Google или Mozilla, объявили по несколко раз, что их браузеры прекратят поддерживать SHA-1 сначала к 2016, потом 17, ну, вот буквально с 1 января google перестал поддержку...
Работа алгоритма
SHA-1 работает путем подачи сообщения в виде битовой строки и создания 160-битного значения хеш-функции, известного как дайджест сообщения .
Дайджест сообщения SHA-1 оценивается с использованием дополненного сообщения. При оценке используются два буфера, каждый из которых состоит из пяти 32-битных слов и последовательности из восьмидесяти 32-битных слов. Слова первого буфера из пяти слов помечены как A, B, C, D и E. Слова второго буфера из пяти слов помечены как H0, H1, H2, H3 и H4 . Слова последовательности из восьмидесяти слов обозначены как W0, W1, W2, W 79. SHA1 обрабатывает блоки по 512 бит при оценке дайджеста сообщения. Весь экстент по длине дайджеста сообщения должен быть кратным 512. В архитектуре SHA-1 для повышения пропускной способности одновременно применяются разнообразные методы ускорения, такие как предварительное вычисление, развертывание цикла и конвейерная обработка.
Алгоритм
(псевдокод)
Функции используемые в алгоритме в i-х итерациях:
0 <= i <= 19 f(i, B, C, D) = (B ∧ С) ∨ ((¬B) ∧ D)
20 <= i <= 39 f(i, B, C, D) = B ⊕ C ⊕ D
40 <= i <= 59 f(i, B, C, D) = (B ∧ С) ∨ (B ∧ D) ∨(C∧D)
60 <= i <= 79 f(i, B, C, D) = B ⊕ C ⊕ D
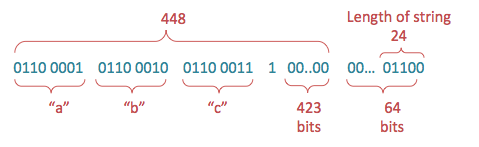
Предположим, что сообщение 'abc' должно быть закодировано с использованием SHA-1, и в двоичном виде оно выглядит, как:
в 16-ричном же виде:01100001 01100010 01100011
1) Инициализируем пять случайных строк шестнадцатеричных символов, которые будут служить частью хэш-функции:61263
2) Затем сообщение дополняется путем добавления 1, с последующим достаточно 0s , пока сообщение не будет 448 бит. Длина сообщения, представленная 64 битами, затем добавляется в конец, создавая сообщение длиной 512 бит:H0 = 67DE2A01
H1 = BB03E28C
H2 = 011EF1DC
H3 = 9293E9E2
H4 = CDEF23A9
3) Дополненный ввод, полученный выше, после этого делится на 512-битные порции, и каждый фрагмент дополнительно делится на шестнадцать 32-битных слов. В случае 'abc' есть только один фрагмент, так как общее сообщение составляет менее чем 512 бит.
4) Для каждого блока используется 80 итераций, необходимых для хеширования, и выполняются следующие шаги для каждого блока:
1.Для итераций с 16 по 79 выполняется следующеее:
2. Теперь выполняется операция побитового сдвига словаW(i)= S(W(i-3)⊕W(i-8)⊕W(i-14)⊕W(i-16))
Таким образом, это эквивалентно круговому сдвигу.S^n(X) = (X<<n)||(X>>32-n)
5) Теперь сохраняем значения хеш-функции, определенные на шаге 1:
6) На 80-х итерациях вычисляется следующее значениеA = H0
B = H1
C = H2
D = H3
E = H4
И переназначаем следующие переменные:temp = S^5 * A + f(i, B, C, D) + E + W(i) + K(i)
7) Прибавляем результат куска хеш-функции к общему значению хеша, как показано ниже, и приступаем к выполнению следующего куска:E = D
D = C
C = S^30(B)
B = A
A = temp
8) На последнем этапе, когда все куски были обработаны, дайджест сообщения представляется в виде 160-битной строки (из 5 хэшированных значений, которые складываем):H0 += A
H1 += B
H2 += C
H3 += D
H4 += E
Таким образом, строка 'abc' будет представленна в виде хеша, похожего на a9993e364706816aba3e25717850c26c9cd0d89d.H = S^128(H0) + S^96(H1) + S^64(H2) +S^32(H3) + H4